Live
LinkedCulture
Unified Cultural Search
LinkedCulture Project Overview
A layered discovery prototype for open-access cultural heritage records across major museum collections. The current prototype searches over 300K collection objects from the Getty Museum (59,979), Art Institute of Chicago (58,443), Rijksmuseum (47,156), Paris Musées (41,564), Cleveland Museum of Art (41,279), MIA (33,591), Joconde (10,000), Harvard Art Museums (6,509), and Metropolitan Museum of Art (4,277). LinkedCulture combines keyword retrieval, semantic similarity, topic clustering, and shareable visual interfaces while preserving the institutional record as the authoritative object shown to users. The architecture places AI at the representation layer, not the interpretation layer: AI helps records become findable, but does not rewrite or replace museum metadata. Built on Ollama embeddings and Qdrant with a custom ingestion pipeline that can be rerun against updated collections and extended to additional institutions.
Published paper
Discovery architecture for cultural heritage
Layered retrieval, institutional authority, and the limits of keyword search
Zenodo · May 27, 2026 · CC BY 4.0
Central claim
AI belongs at the representation layer, not the interpretation layer.
LinkedCulture helps users find authoritative museum records. It does not generate, rewrite, or interpret those records for them.
- Scope
- 8 cultural heritage institutions
- Scale
- 300k+ open-access records
- Architecture
- Keyword + semantic + query mediation
Abstract
Cultural heritage discovery systems were designed for a retrieval environment that no longer fully describes the people who use them. The vocabulary of the cataloger and the vocabulary of the searcher are not the same, and no refinement of keyword search has been able to close that gap. This paper argues that the answer lies in a layered discovery architecture that combines keyword retrieval, semantic similarity, and AI-assisted query mediation, while preserving the authoritative institutional record as the only thing the end user ever sees. The central architectural principle is that AI belongs at the representation layer, not the interpretation layer. The system helps users find records. It does not generate, rewrite, or interpret them. LinkedCulture, an open-source prototype built across eight cultural heritage institutions and more than 300K records, demonstrates this architecture in operation and documents three observations from its deployment: that layered retrieval surfaces records keyword search alone misses, that neither retrieval mode dominates unconditionally across query types, and that a shared representational space appears to mediate vocabulary inconsistency across institutional boundaries in ways that single-institution search cannot replicate. The implications for how cultural heritage institutions approach discovery infrastructure, retrieval evaluation, and the appropriate role of AI in their systems are discussed.
Published paper · No. 2
Embedding cultural heritage metadata
Pipeline design, multilingual retrieval, and hybrid search in LinkedCulture
Zenodo · June 10, 2026 · CC BY 4.0
Central contribution
Structured metadata is rewritten as natural-language prose before embedding.
The model encodes the relationships it learned from prose, not isolated catalog field values — a documented, reproducible pipeline pattern for hybrid retrieval across heterogeneous institutions.
- Prose over concatenation
- Metadata is presented as sentences, not semicolon-separated fields, to match the embedding model's training distribution
- Cross-language interference is predictable
- English queries found false proximity to Dutch records; migrating to a multilingual model is the direct mitigation
- Embedding models fail predictably
- Negation, paradox, and sparse metadata return confident-looking but wrong results; metadata quality drives retrieval quality
Abstract
This paper describes the implementation behind LinkedCulture, an experimental cross-institutional cultural heritage retrieval prototype. It explains how structured cultural heritage metadata is translated into embeddable prose, how records from eight institutions are normalized into a canonical schema, how OpenSearch and Qdrant support keyword and semantic retrieval, and how Reciprocal Rank Fusion combines the two ranking signals.
The paper documents a transition from English-centered to multilingual embedding prompted by an observed cross-language retrieval failure, and reports preliminary observations on cross-lingual retrieval behavior in the extended index. It also examines where pipeline design choices introduce potential bias, where embedding models fail in predictable ways, and how metadata density, institutional imbalance, licensing constraints, and local infrastructure choices shape retrieval behavior.
This is the second paper in the LinkedCulture research paper series.
Published paper · No. 3
Semantic clusters and language partitioning
Language partitioning in a multi-institutional cultural heritage index
Zenodo · June 24, 2026 · CC BY 4.0
Central contribution
Multilingual retrieval and cross-lingual representation are not the same thing.
The multilingual model made records findable within each language but left the embedding space partitioned by language. Cross-language discovery, at this scale, is an orchestration problem — not a solved representation problem.
- Near-total language siloing
- French records' nearest neighbors were 99.9% French, though French records were only 17.0% of the 302,798-record corpus
- No single model fixes it
- Alternative multilingual models narrowed cross-language distance but never eliminated the partition or produced reliable cross-language ranking
- Orchestration over model choice
- Query translation beat model substitution; RRF was replaced by normalized-score fusion after it elevated weak candidates in sparse-metadata environments
Abstract
The first paper in the LinkedCulture series argued that keyword search alone is insufficient for cultural heritage discovery, because the vocabulary of the cataloger and the vocabulary of the searcher often do not overlap. The second paper described the implementation of a hybrid retrieval system combining keyword search and semantic similarity across a multi-institutional cultural heritage corpus. That implementation adopted a multilingual embedding model after an English-centered embedding setup produced a visible retrieval failure when non-English records entered the index.
This paper reports what happened after that change was tested at larger scale. The central finding is that multilingual retrieval and cross-lingual representation are not the same thing. The multilingual embedding model used by LinkedCulture made records retrievable within multiple languages, but it did not produce a unified cross-language semantic space. French-language records overwhelmingly clustered with other French-language records, while English-language records overwhelmingly clustered with English-language records, even when records from different languages described conceptually related material.
The finding emerged from analysis of a corpus of 302,798 cultural heritage records, including a French-language bloc large enough to make language partitioning visible as structure rather than noise. Nearest-neighbor analysis showed near-total language siloing: French records' nearest neighbors were 99.9% French despite French records comprising only 17.0% of the corpus. Model bake-off experiments further showed that alternative multilingual text embedding models reduced measured cross-language distance but did not eliminate the partition or produce reliable cross-language ranking. Query translation, rather than model substitution, produced the strongest cross-lingual retrieval improvement.
The paper also documents a related operational evolution in LinkedCulture's hybrid retrieval layer: the replacement of Reciprocal Rank Fusion with normalized-score fusion and a coordination factor after production use revealed that RRF could elevate weak candidates in sparse-metadata environments. Together, these findings suggest that practical cross-institutional cultural heritage retrieval depends less on selecting a single superior model than on designing orchestration layers that compensate for the structural behavior of models, metadata, and ranking systems. For multilingual cultural heritage indexes, cross-language discovery is presently an orchestration problem, not a solved representation problem.
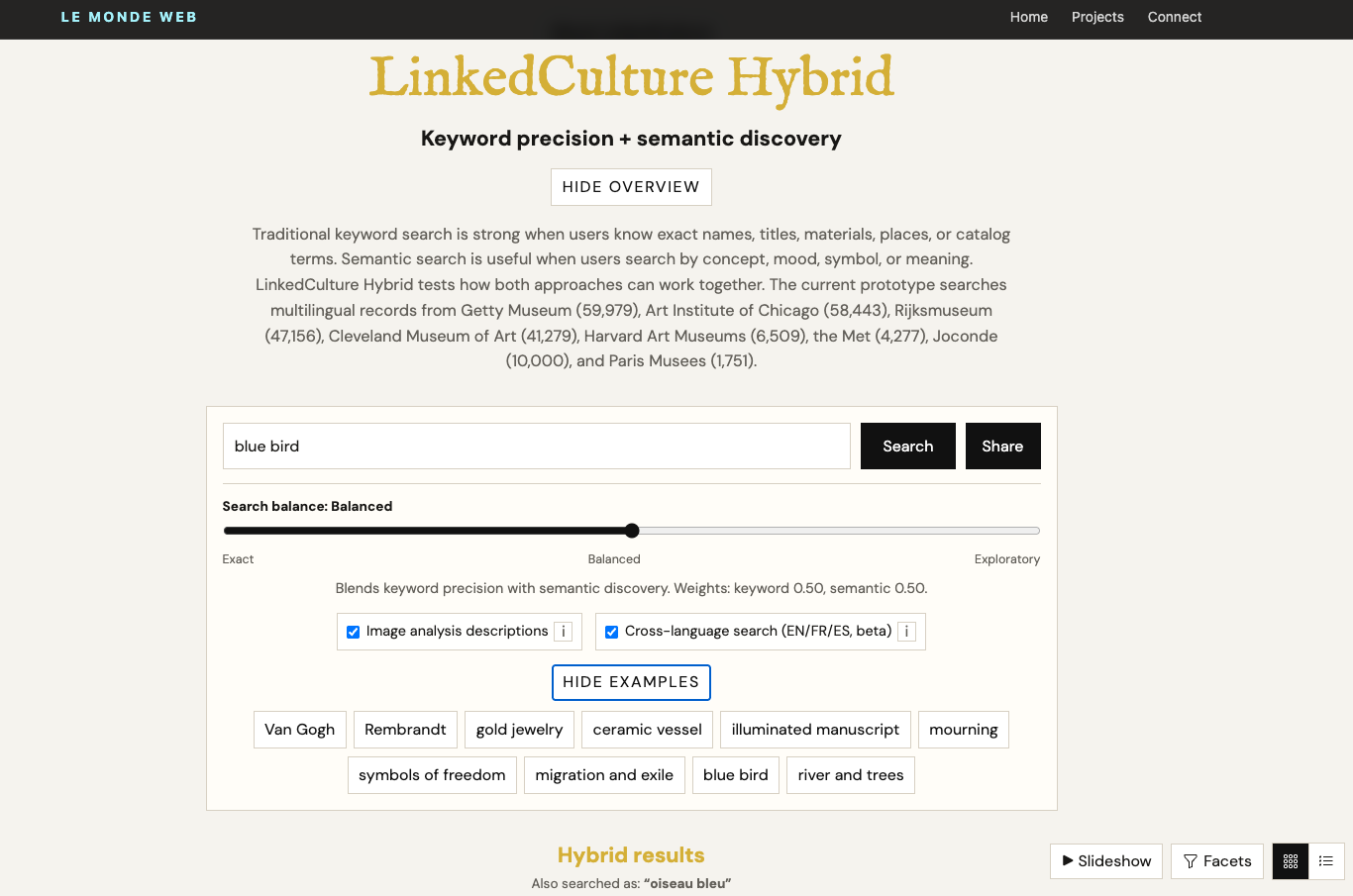
Live prototype
Try the hybrid search described in the paper.
The hybrid interface combines keyword retrieval with semantic similarity and lets users tune the balance between exact search and exploratory discovery. It is the clearest public demonstration of LinkedCulture's layered retrieval architecture.
LinkedCulture Topics
Extends the same index into unsupervised discovery. Each cluster is labeled using the object descriptions and promoted to a draft topic for editing. The result is a set of thematic groupings that emerge purely from the geometry of the embedding space: objects that land near each other semantically, regardless of institution, date, or catalog category. Topics are a way of reading what the model already knows about the collection. To date, the system has identified over 1,939 clusters across 92 published topics, each under review before publishing. LinkedCulture Topics are then folded back into the semantic search results to enrich discovery further.
Who It Serves
Museums, archives, libraries, researchers, digital humanities teams, and cultural heritage organizations exploring keyword and semantic discovery across collections.
Pilot Fit
LinkedCulture can be piloted with one museum collection, a focused subset of records, or a small cross-institutional set. A pilot turns existing collection data into a working semantic, keyword, or hybrid search prototype. The museum can use the prototype privately, connect results to an existing website, or choose to include approved records in the broader LinkedCulture multi-institution discovery index.
Shared Process
From fragmented inputs to usable outputs.
Ingest open-access cultural metadata
Generate metadata embeddings
Index in vector database
Hybrid search, keyword and semantic search by concept, material, or meaning